1 简介
文本生成是自然语言处理中一个重要的研究领域,具有广阔的应用前景。当前主流的用来进行文本生成的模型主要是Seq2Seq模型,通常利用maximum likelihood和teacher forcing进行训练,生成文本的质量也大都通过validation perplexity来衡量。
目前的文本生成模型也存在着一些问题,其对于perplexity的优化来说效果可能很好,但却不能保证生成质量足够好的文本,因为其并没有针对输出明确定义一个损失函数来提高结果质量。而本文对此做了改变,选择用GAN的模式对生成过程进行训练。然而,传统的GAN模型无法解决自然语言处理中词向量的离散性问题,因此在这篇论文中利用强化学习中的 actor-critic 算法来训练生成器,利用最大似然和随机梯度下降来训练判别器。另外,GAN 模型中的模式崩溃和训练不稳定问题在文本生成任务下也更严重。训练不稳定会随着句子的长度增加而加重。为了避免这两个问题的影响,本文选择了对缺失词进行完形填空的生成模式,而不再让生成器来生成的完整的文本。
2 准备知识
2.1 Seq2Seq模型
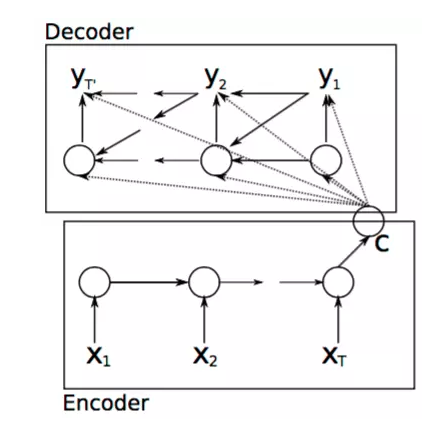
基本的Seq2Seq模型如上图所示,整个模型分为解码和编码的过程,编码的过程结束后输出一个语义向量c,之后整个解码过程根据c进行相应的学习输出。而对于解码过程,对应的是另外一个RNN网络,其隐藏层状态在t时刻的更新根据如下方程进行更新:
\[h_t = f(h_{t-1},y_{t-1},c)\]生成的单词的条件概率可以写成:
\[P(y_t|y_{t-1},y_{t-2},...,y_1,c) = g(h_t,y_{t-1},c)\]对于整个输入编码和解码的过程中,使用梯度优化算法以及最大似然条件概率为损失函数去进行模型的训练和优化:
\[\max_{\theta}\frac{1}{N}\sum_{n=1}^N log p_{\theta}(y_n|x_n)\]其中$\theta$为相应模型中的参数,$(x_n,y_n)$是相应的输入和输出的序列。
2.2 生成对抗网络(GAN)
GAN网络包括生成器$G_\theta(Z)$和判别器$D_\phi(X)$两部分。生成器将噪音z映射到输入空间中,尽可能和真实数据相近,判别器则用来判断输入x来自真实数据的概率大小。优化目标为:
\[\min_G\max_DV(D,G) = \Bbb{E}_{x\sim{p_{data(x)}}}[logD(x)] + \Bbb{E}_{z\sim p_z(z)}[1-D(G(z))]\]其中G通过不断地学习去生成质量更好的样本来欺骗判别器D,而判别器D则通过不断地学习来分辨出由生成器G生成的数据和真实数据。
2.3 强化学习
强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决 decision making 问题,即自动进行决策,并且可以做连续决策。
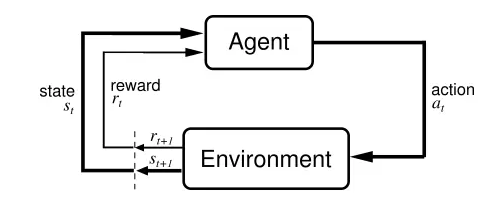
主要包含四个元素,agent,环境状态,行动,奖励, 其中智能体agent与环境environment进行交互,agent每采取一个动作a环境就会给予智能体一定的反馈reward,强化学习的目标就是获得最多的累积奖励,通过累积奖励对agent的动作进行建模,从而学习出如何在不同的状态进行不同的决策。
3 MaskGAN
$(x_t,y_t)$是输入和目标的序列,
模型基于Seq2Seq框架,对于一个离散的句子序列$x = (x_1,x_2,…,x_T)$,通过0/1的掩码序列$m = (m_1,m_2,….,m_T)$当$m_t$是0时,$x_t$被替换为空白词
3.1 Generator
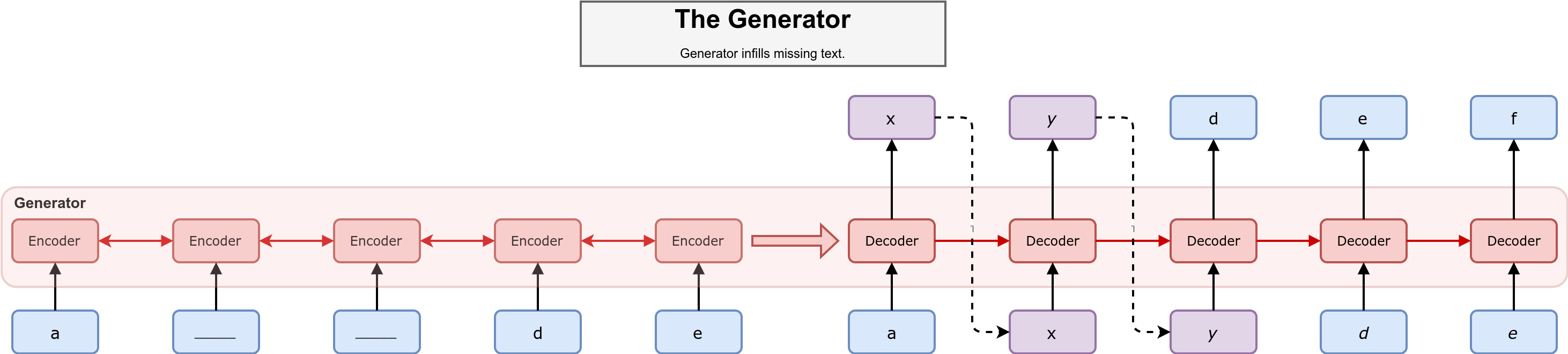
生成器模型如上图所示,采用Seq2Seq框架,其中蓝色的单元为已知的单词,紫色的单元为需要进行推断的单词,虚线的部分是基于生成器的概率分布进行采样的过程。在编码器部分读入掩码后的序列$m(x)$,其中被掩盖的部分我们用下划线来表示。在解码器部分则是通过编码器的隐藏状态来推断被掩盖部分的单词:
\[P(\hat{x},..,\hat x_T|m(x)) = \prod_{t=1}^TP(\hat x_t|\hat x_1,...,\hat x_{t-1},m(x))\]然后根据概率分布:
\[G(x_t) \equiv P(\hat x_t|\hat x_1,...,\hat x_{t-1},m(x))\]进行采样操作,从而获得在t时刻的生成结果。在上图的例子中,生成器应当按照字母表的顺序来对序列进行填空。
由于自然语言处理任务中分布式词向量的离散性,不能直接使用GAN模型来完成生成器的训练,因此本文引入了强化学习的方法,将生成单词视为智能体的动作,判别器对于生成器的评价作为奖励,通过Policy Gradient方法来对生成器模型进行训练:
\[\nabla_\theta\Bbb{E}[R] = \Bbb{E}_{\hat x_t\sim G}[\sum_{t=1}^T (R_t-b_t)\nabla_{\theta}log(G_{\theta}(\hat x_t))]\\ = \Bbb{E}_{\hat x_t\sim G}[\sum_{t=1}^T (\sum_{t=1}^T \gamma_sr_s-b_t)\nabla_{\theta}log(G_{\theta}(\hat x_t))]\]其中generator的目标就是使生成的结果从discriminator得到的最终的回报最大。$G_\theta$代表计算生成的$\hat x_t$概率的函数,$R_t$代表 discriminator 给在当前状态下采取动作$\hat {x_t}$得到的长期回报,$b_t$是为了防止强化学习训练过程中梯度的方差过大,给回报值增加一个baseline。其中$R_t = \sum_{s=t}^T\gamma^sr^s$,$R_t$以及$b_t$是通过蒙特卡罗采样计算得到的。
3.2 Discriminator
discriminator 采用的结构和generator是一致的,都是seq2seq的形式, 只不过在每个时间步输出一个标量的概率:
\[D_\phi(\hat x_t|\widetilde x_{0:T},m(x)) = P(\hat x_t|\widetilde x_{0:T},m(x))\]由此我们可以设定出对生成器模型的奖励:
\[r_t = logD_\phi(\hat x_t|\widetilde x_{0:T},m(x))\]并以该奖励完成对生成器模型部分的训练过程。
而判别器部分的训练方式与传统的seq2seq的训练方式一致,均是采用maximum likelihood作为目标。它的输入是masked sequence 和 filled-in sequence,根据这两个判断t时刻的词是否为ground-truth。其训练目标如下:
\[\nabla_{\phi}\frac{1}{m}\sum_{i=1}^m[logD(x^{(i)})] + log(1-D(G(z^{(i)})))\]3.3 算法

4 总结
本文使用了GAN和强化学习方法Actor-Critic结合的方式来进行文本的生成,相对于之前SeqGAN的工作确实有很大的提升,可以产生具有更好质量的文本。而使用完型填空的方式来进行文本生成,有助于来缓解GAN学习中的模式崩溃问题,稳定GAN的训练过程。